Why Your AI Needs a Self-Improvement System (And What One Actually Looks Like)
The Problem Nobody Talks About
Here's something that doesn't get mentioned enough when people sell you on AI tools: most of them forget everything.
You spend an hour in a session correcting tone, fixing format, teaching the system how your business works. You close the tab. The next session, it's back to day one. Every correction you made is gone. Every "don't do that" you said has been forgotten.
For a one-off task, that's fine. For a business that runs on AI day after day across dozens of clients — it's a fundamental reliability problem.
That's what we set out to fix.
What Self-Improvement Actually Means
When we talk about AI self-improvement, we don't mean the AI rewriting its own code or updating its base model. That's not what's happening here, and it's important to be clear about what this actually is.
Self-improvement, in practice, means building a system around your AI that:
- Captures corrections and behavioral notes from real sessions
- Analyzes patterns across those corrections over time
- Proposes targeted changes to the skill files and instructions that guide the AI's behavior
- Tests those proposed changes before they go anywhere near production
- Deploys only the ones that actually improve performance
- Does all of this automatically, on a schedule, without you having to manage it
It's not magic. It's a feedback loop with a quality gate. But when it's working, the effect compounds. Each correction feeds future sessions. The system gets measurably better over time instead of staying flat.
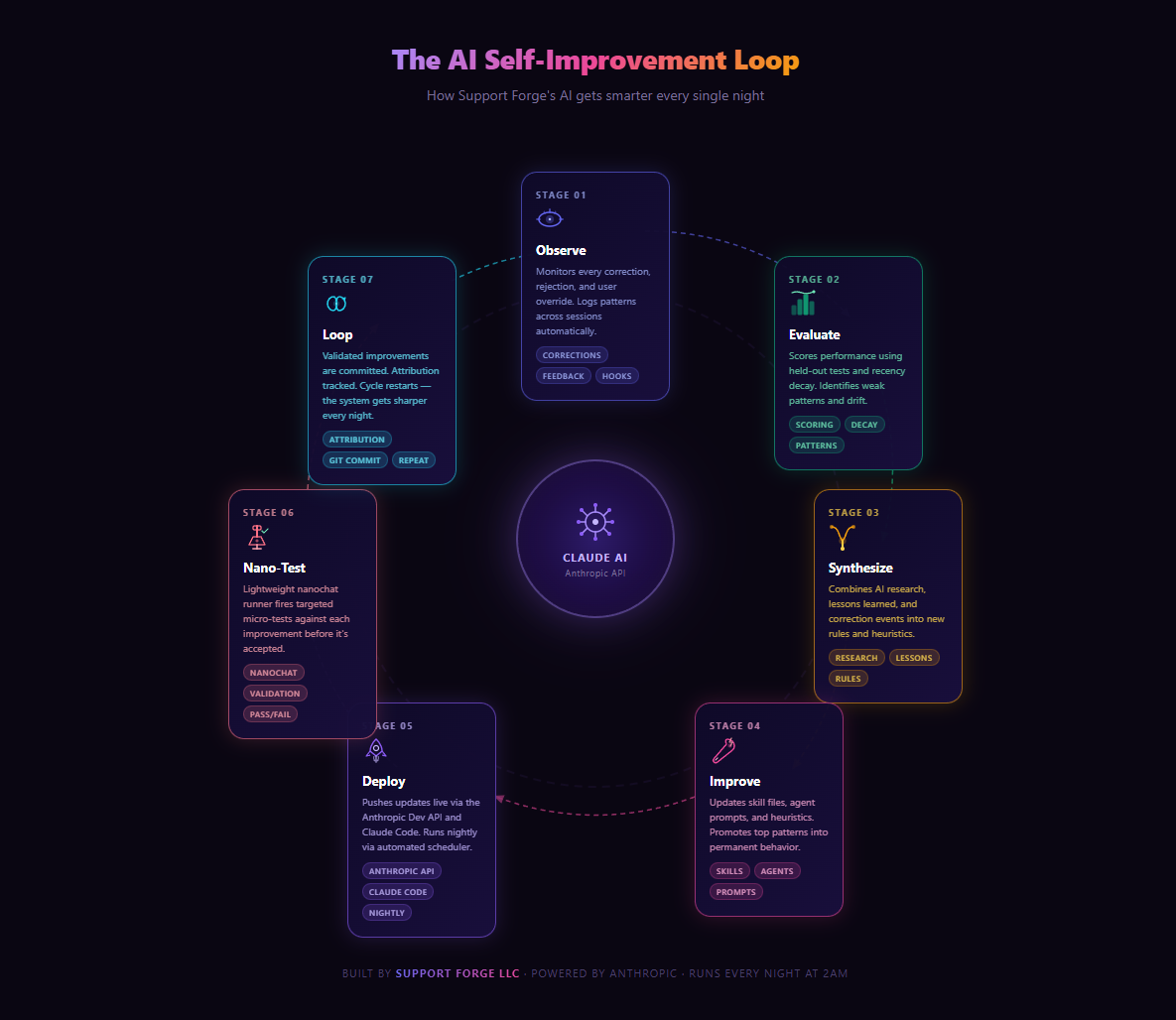
How Ours Works
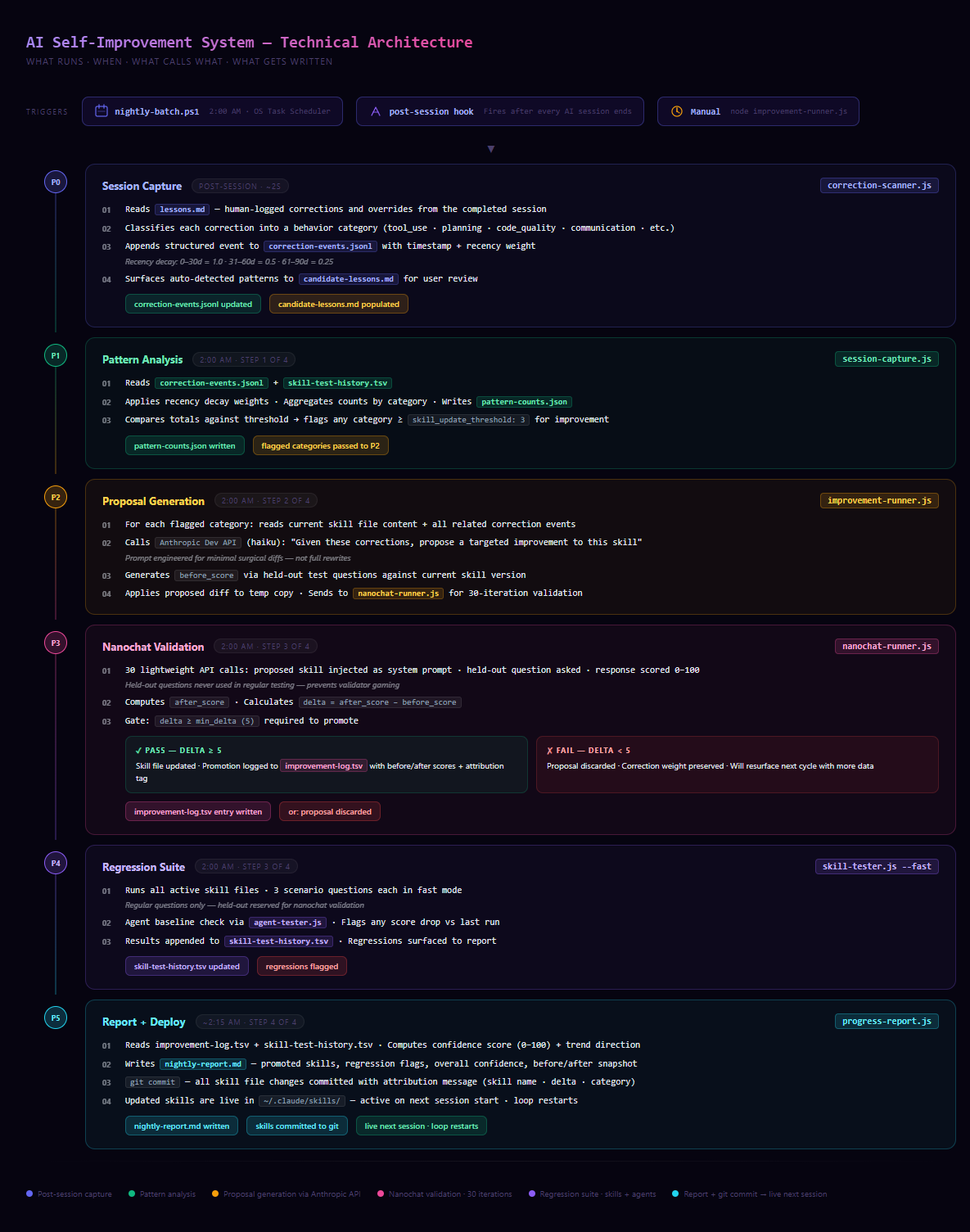
We built a six-phase pipeline that runs every night at 2 AM.
Phase 0 — Capture. A post-session hook fires automatically after every AI session ends. It reads the correction log, classifies each note by behavior category, and appends it to a running archive with a timestamp and recency weight. Corrections from the last 30 days count four times more than ones from 90 days ago. Recent feedback matters more.
Phase 1 — Pattern analysis. The pipeline reads the archive and looks for categories that have hit the threshold for improvement — places where the same type of correction has come up enough times that it's clearly a pattern, not a one-off.
Phase 2 — Proposal generation. For each flagged category, it calls the Anthropic API with the current skill file and all related corrections and asks for a targeted improvement. The prompt is engineered for minimal surgical changes — not full rewrites. Small, specific diffs that address exactly what went wrong.
Phase 3 — Validation. This is the most important part. Every proposed change runs through 30 API iterations against a held-out question set — questions that are reserved specifically for testing and never used in regular training. It computes a before score and an after score. The delta has to be 5 or higher for the proposal to advance. Anything below that gets discarded.
Phase 4 — Regression testing. Even after a proposal passes the delta gate, it runs through a full regression suite across all 49 skills and 264 agents to make sure it didn't break anything it wasn't supposed to touch.
Phase 5 — Deploy and report. Passing changes are committed to git with attribution tracking. A confidence score and nightly report are generated by 2:15 AM. The improvements go live on the next session start.
Four Months of Real Data
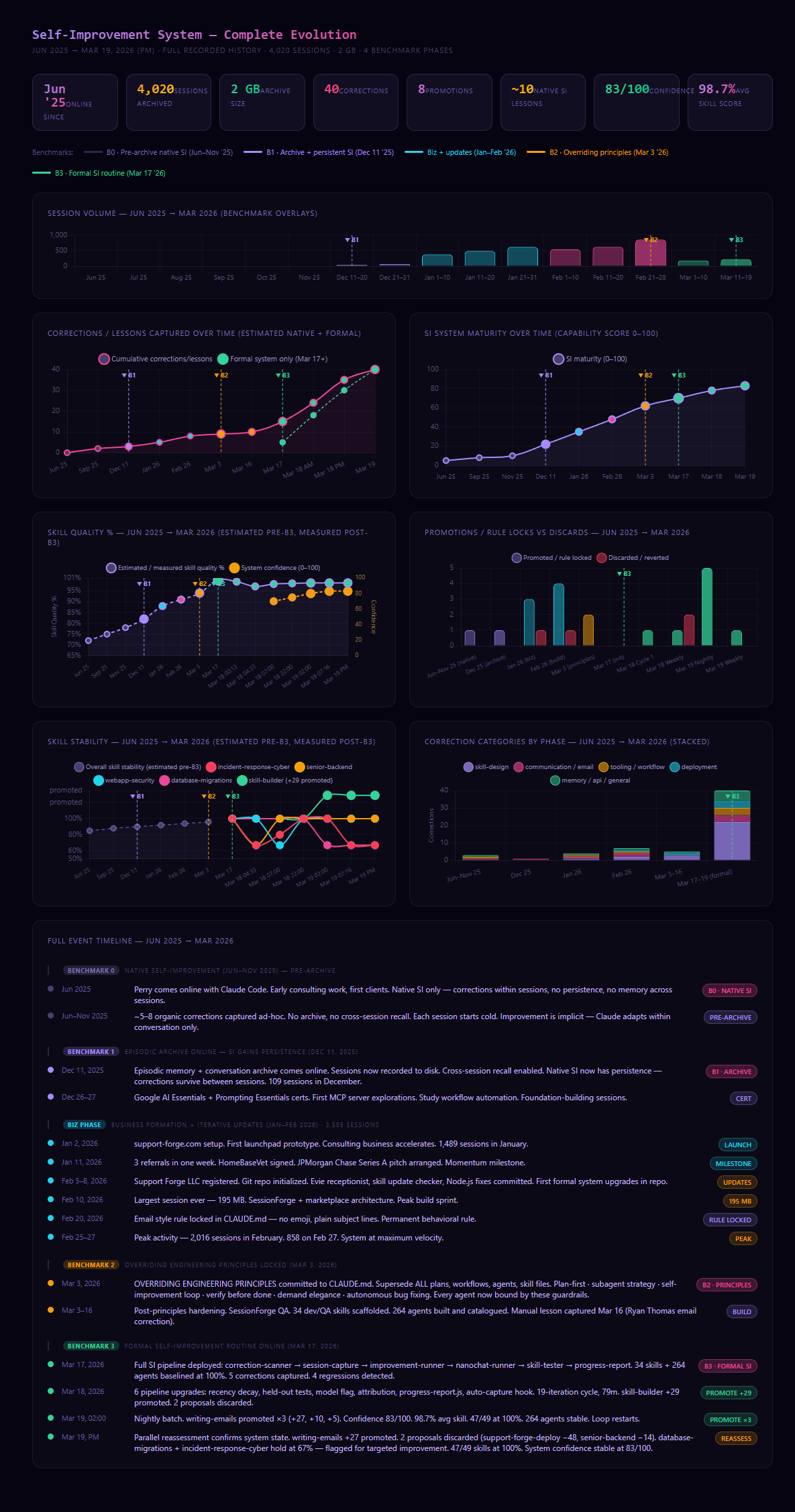
We've been running the archive since December 2025 and the formal pipeline since March 2026. Here's what the numbers actually look like after four months:
4,020 sessions have been archived. 40 corrections have been processed through the system. 8 improvements have been promoted to production. 4 proposals were discarded by the quality gate.
The average skill score across all 49 measured skills is 98.7%. System confidence sits at 83 out of 100.
That last number — the 4 discards — is the one that makes the whole thing worth running. One of those discarded proposals was for our deployment skill. It scored negative 48. Without the gate, that would have shipped and degraded behavior across every agent that touches deployment. Instead it got blocked, the correction weight was preserved, and it'll inform the next cycle with better data behind it.
The gate doesn't just protect quality. It protects you from the system getting worse while trying to get better.
What It Can Do
This kind of system can compound behavioral improvement over time. A correction made today feeds sessions six months from now. It can catch patterns you wouldn't notice manually — the same category of mistake appearing across dozens of sessions is easy to miss when you're in them one at a time. It can validate changes before they go live, so you're not testing on production. And it can do all of this without anyone manually reviewing every proposed change.
It also creates a paper trail. Every promotion is logged with before and after scores, attribution, and a timestamp. You can see exactly what changed, when, and by how much. That's useful for auditing, for client transparency, and for understanding what's actually driving quality over time.
What It Can't Do
It cannot retrain the underlying model. Claude is Claude. What this system does is shape how Claude behaves within the instructions and skill files you give it — it doesn't reach into the model weights.
It doesn't guarantee perfect recall. The archive search is approximate. Some corrections will surface more reliably than others based on how they were logged and how similar they are to the pattern being analyzed.
It doesn't eliminate human judgment. The two skills currently below 100% — database migrations and incident response for cybersecurity — are volatile by design. Those are high-stakes domains where the right answer genuinely depends on context that no automated system should be making calls on. The volatility flag is the system correctly identifying where a human needs to stay in the loop.
And it doesn't run in real time. The nightly batch means that a correction made at 11 PM might not be tested and deployed until 2 AM the following night. The post-session capture is immediate, but the actual improvement cycle has a lag.
Why It's Still Worth Building
Even with all of those limitations, a self-improvement system matters for one simple reason: consistency.
If you're using AI across a business — multiple clients, multiple sessions, multiple use cases — you need the system to behave the same way every time. Same quality standard. Same tone. Same rules. Without some form of persistence and feedback loop, you're relying entirely on whatever the base model does by default, plus whatever instructions you can fit into a prompt. That ceiling is low.
The self-improvement system raises the floor. Every cycle, the worst behaviors get caught and corrected. The quality gate means nothing gets worse. Over time, the gap between what the AI does by default and what it should do for your specific business gets smaller.
That's not a flashy outcome. It's not the kind of thing that makes for a great demo. But it's the thing that makes AI actually reliable at scale — and reliable is what turns an interesting tool into infrastructure you can build a business on.
---
If you're thinking about how to build consistent AI behavior across your business or your clients', book a discovery call. This is the architecture work we do every day.
Related Articles
When the Helpful Assistant Confabulates: A Catalyst Acoustics × Support Forge Whitepaper
A forensic write-up of a real production incident — a Claude Code agent that confidently reported writing to production when it had not — and the three-tier framework we built in response. Co-authored with Pam Marengo at Catalyst Acoustics.
I Built a Tool to Run Claude Code From My Phone. It Became a Product.
The origin story behind SessionForge — how a personal SSH dashboard built for one use case turned into a full session management platform for AI development teams.
We Built an AI That Learns From Its Own Mistakes — Every Night
Most AI tools forget everything the moment a session ends. We built a self-improvement pipeline that automatically captures corrections, validates them, and deploys better behavior every night at 2 AM. Here's how it works and what 4 months of data shows.
Subscribe to The Forge
Practical takes on AI, automation, and IT for small and mid-sized businesses. New posts, delivered when they're ready.
We'll only use your email to send The Forge. No spam, unsubscribe anytime.